")
一张好的模型架构图能让读者一眼看懂你的网络:层的顺序、流经其间的张量维度,以及那些有意思的模块都在哪里。但手绘很慢,而通用图像 AI 又会把标签弄成乱码。本指南提供 24 个开箱即用的神经网络结构图提示词、一个可复用的提示词模板,以及真实生成的示例,让你能用 AI 在几分钟内做出干净、带标注、论文可用的架构图——无需矢量软件,也不需要绘画功底。
读完本指南后,你将能够:
- 用一句话生成 CNN 架构图、Transformer 架构图、RNN/LSTM 图、MLP 图、U-Net 图和机器学习流程图。
- 用一个简单的四段式模板,把任意提示词改写成贴合你自己模型的版本。
- 避开那些让 AI 神经网络图"看起来不对"的常见错误。
把下面任意一条提示词粘贴进神经网络结构图生成器,然后通过要求添加层、标注张量维度、改色或重新标注来微调结果——或在 SciDraw AI 编辑器中打开继续迭代。
一条优秀架构提示词的解剖
结果不理想,多半源于提示词太含糊。强有力的神经网络结构图生成器提示词包含四个部分:
- 主体——画什么模型或模块(例如"一个 CNN 图像分类器""一个单独的 LSTM 单元")。
- 按顺序排列的层/模块——从输入到输出列出每一阶段(卷积、池化、注意力、全连接、softmax)。
- 标注/张量维度——给每个模块命名,并在审稿人期待之处要求标出特征图或张量尺寸。
- 风格与方向——"扁平技术示意图、从左到右数据流、带标注的模块、干净的无衬线文字"。
模板:"画出 [模型],含 [按顺序排列的层/模块,输入 → 输出]。标注 [模块名称和张量维度]。采用干净的扁平技术示意图,数据从左到右流动。"
把这句模板放在手边——下面每条提示词都遵循它,当你想在线画一个神经网络时也可以替换成自己的模型。
如何获得干净的架构图
- 按顺序列出各层,并明确输入和输出,让数据流毫不含糊。
- 要求张量维度(例如"标注特征图尺寸"或"标注输出维度"),当你需要一张严谨的模型架构图时。
- 给模块命名——"多头注意力""残差块""跳跃连接"——这样每个模块都画得有区别。
- 指定方向。 从左到右是论文架构图的惯例;从上到下能让很深的堆叠保持可读。
- 图内文字尽量短。 把细节放进图注,而不是塞进图里。
- 迭代,而非重来。 用"在每个卷积后加批归一化"来微调,而不是重写整条提示词。
卷积网络(CNN、ResNet、U-Net)
CNN 配图是最常被需要的深度学习架构图——也是最容易画乱的,因为卷积/池化堆叠和不断变化的特征图尺寸必须标注得干净。先从完整的分类器入手,再延伸到残差块和分割网络。
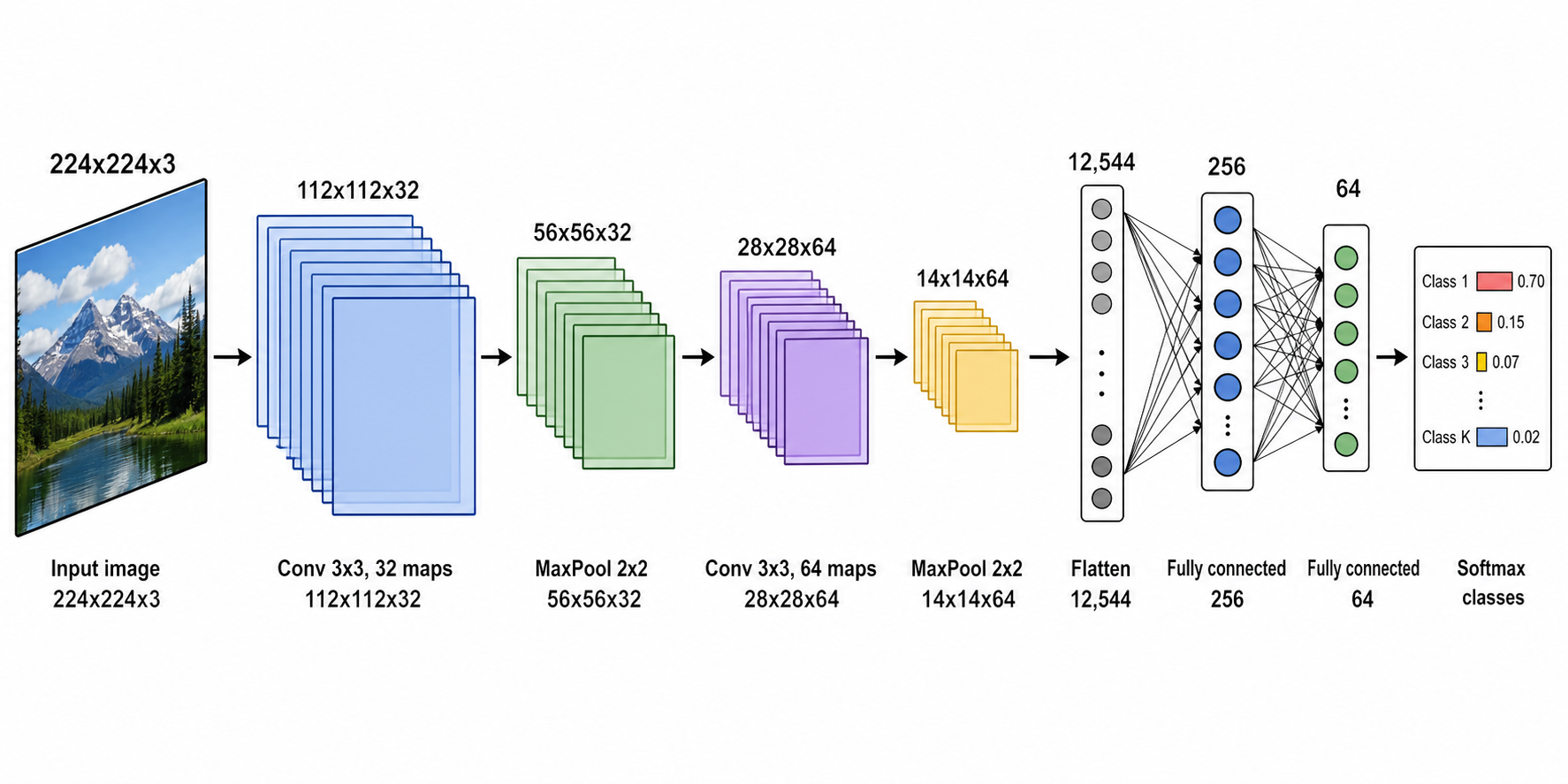
- 画一张 CNN 架构图,从一张输入图像经堆叠的卷积和池化层到展平、两个全连接层和一个 softmax 分类器;标注每一阶段的特征图尺寸(例如 224×224×3 → 112×112×64),并让数据从左到右流动。
- 画一个 ResNet 残差块,展示跳跃(恒等)连接加回到两层卷积路径上,清楚地标注相加操作、ReLU 和批归一化。
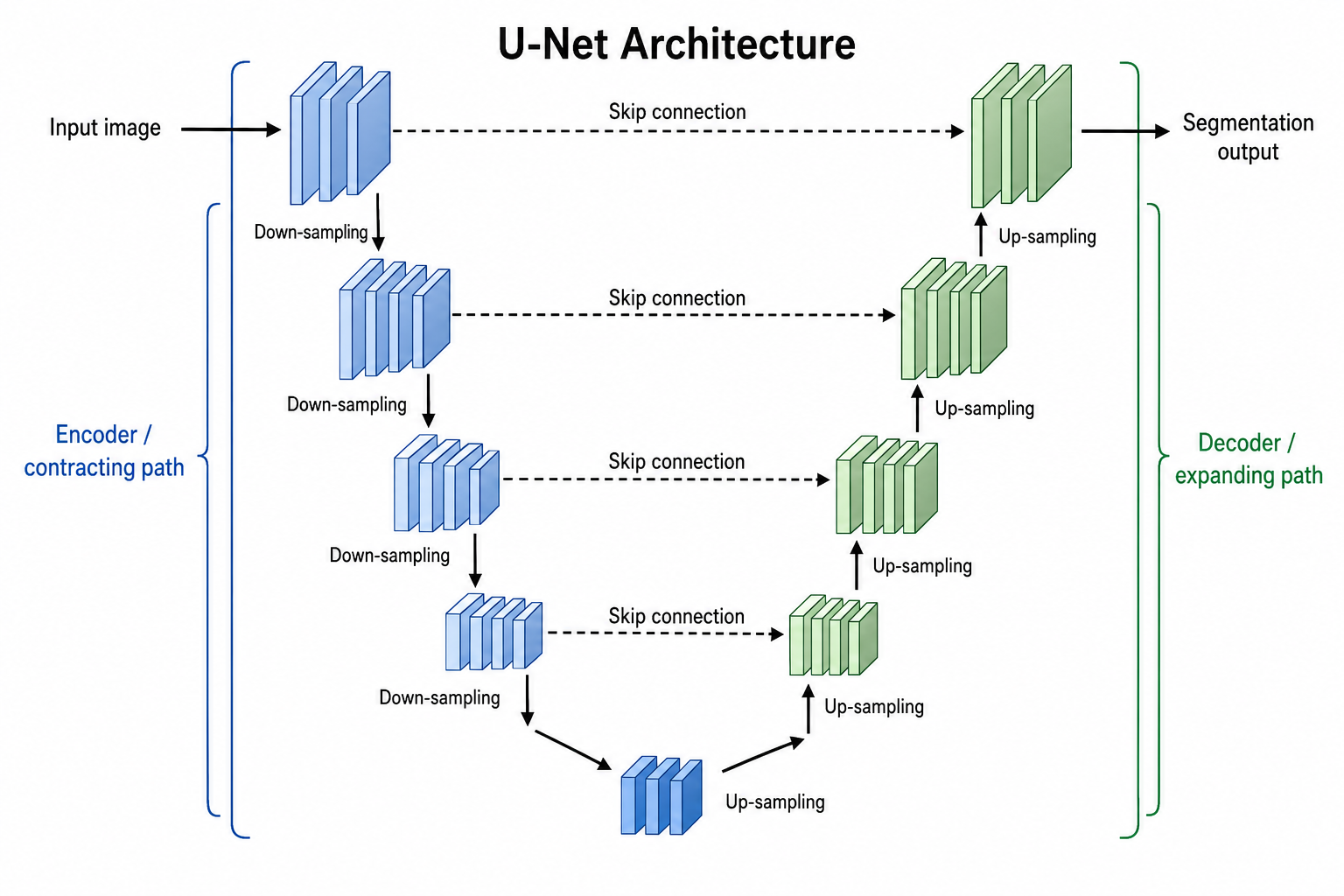
- 画一张 U-Net 图,含其收缩的编码器、扩张的解码器,以及连接对应层级的跳跃连接;标注下采样、上采样、瓶颈层和分割输出掩码。
- 画一个深度可分离卷积块(MobileNet 风格),与标准卷积对比,标注深度卷积和逐点卷积两个阶段以及参数量的节省。
- 画一个带特征金字塔网络(FPN)的视觉主干:一个 CNN 产出多尺度特征图,通过自上而下和横向连接融合,每个层级都标注。
Transformer 与注意力
得益于 LLM 和 ViT,Transformer 架构图如今是搜索量最高的神经网络配图。下面这些提示词涵盖完整的编码器-解码器堆叠、单个注意力块,以及仅编码器 vs 仅解码器的对比。
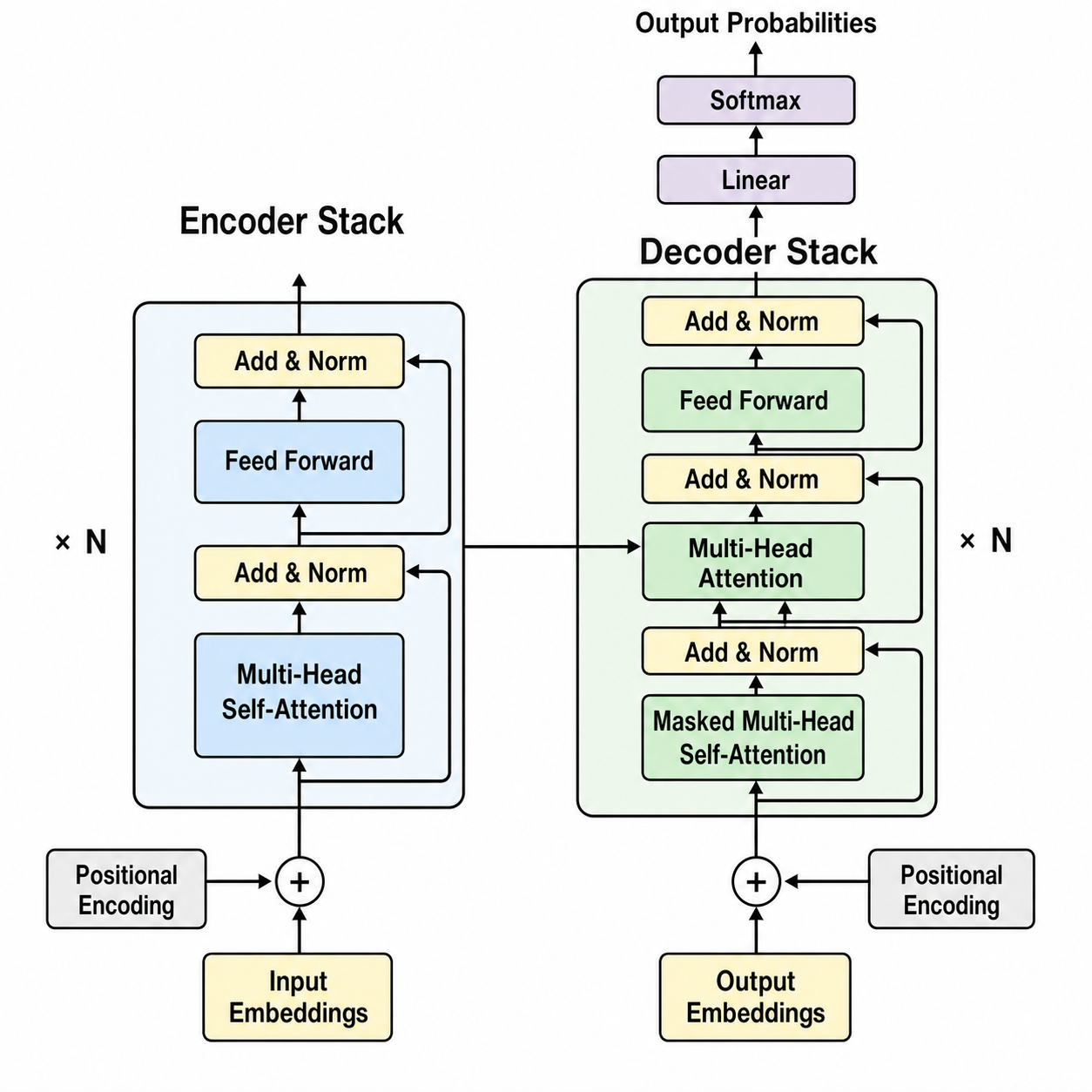
- 画出完整的 Transformer 架构,含堆叠的编码器和解码器块:输入嵌入加位置编码、多头自注意力、前馈子层、Add-and-Norm 残差连接、解码器中的掩码注意力,以及最终的线性加 softmax 输出。
- 画一个单独的多头自注意力块,展示查询、键和值、缩放点积注意力、softmax,以及多个头的拼接,并标注张量维度。
- 画一个视觉 Transformer(ViT),把一张输入图像切分为固定大小的图块、对它们做线性嵌入、在前面加一个分类令牌、加上位置编码,并送入 Transformer 编码器到分类头。
- 把仅编码器的 Transformer(BERT 风格)与仅解码器的 Transformer(GPT 风格)并排画出,标注注意力掩码的差异以及各自的典型任务。
- 单独画出位置编码这一步:一串令牌嵌入与正弦位置向量相加,并清楚地标注。
循环与序列模型(RNN、LSTM、seq2seq)
一张 RNN/LSTM 图必须清楚地表现时间——要么沿时间步展开,要么作为单个带门控的单元。下面这些提示词两者都覆盖,外加经典的编码器-解码器序列模型。
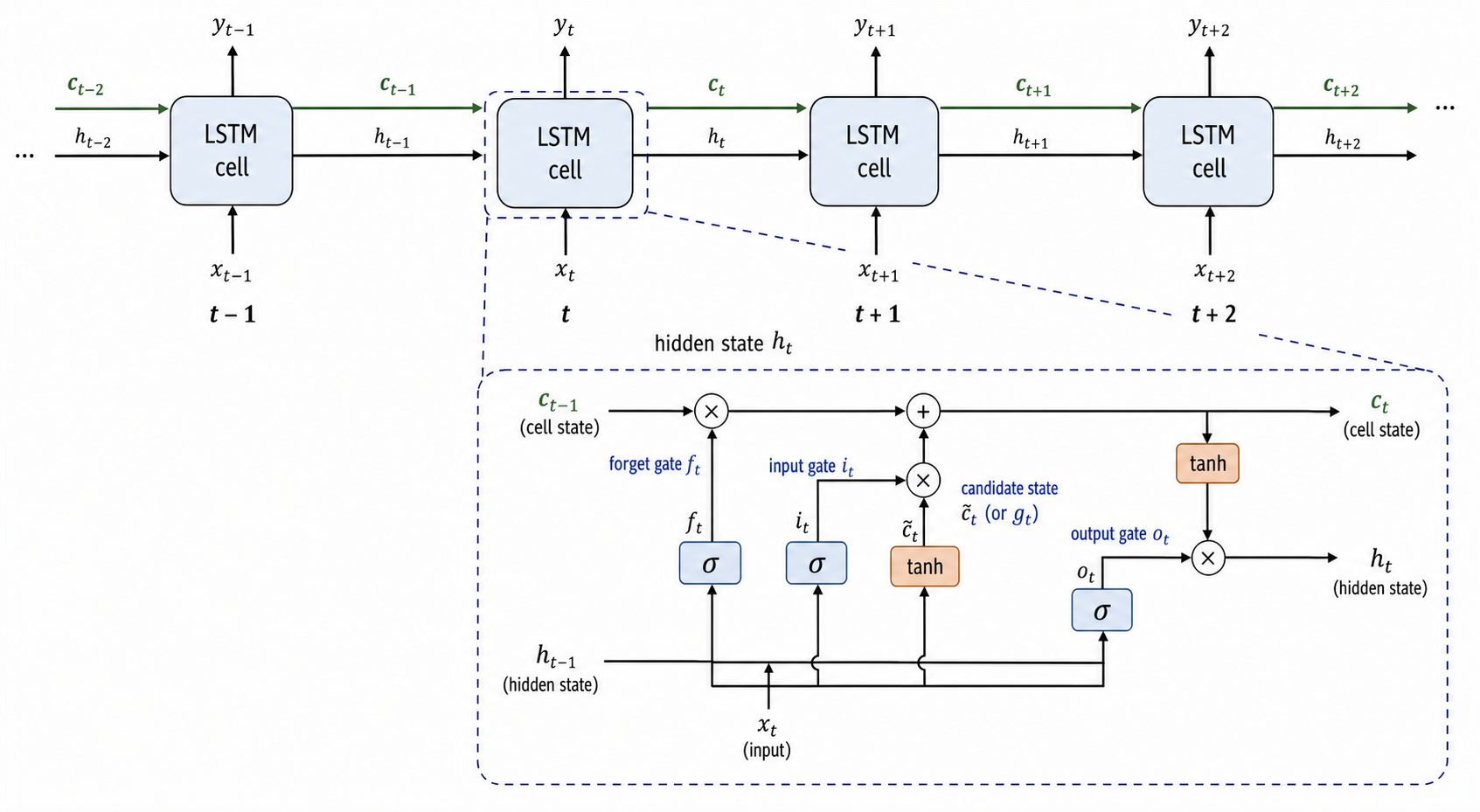
- 画一个循环神经网络沿四个时间步展开,标注每一步的输入、隐藏状态和输出,以及把隐藏状态从一步传到下一步的箭头。
- 画一个单独的 LSTM 单元,展示输入门、遗忘门和输出门、候选值、贯穿顶部的细胞状态,以及门控乘法运算,每个组件都标注。
- 画一个 GRU 单元,与 LSTM 单元对比,标注更新门和重置门,并指出它没有单独的细胞状态。
- 画一个序列到序列模型,含一个把输入压缩成上下文向量的编码器 RNN 和一个生成输出序列的解码器 RNN,并标注它们之间的注意力连接。
- 画一个双向 RNN,正向和反向处理一条序列,并在每个时间步把两个隐藏状态流拼接起来。
经典与生成模型(MLP、自编码器、GAN、扩散)
从教科书式的 MLP 图到现代生成网络,这些都非常适合教学,以及论文的背景章节。
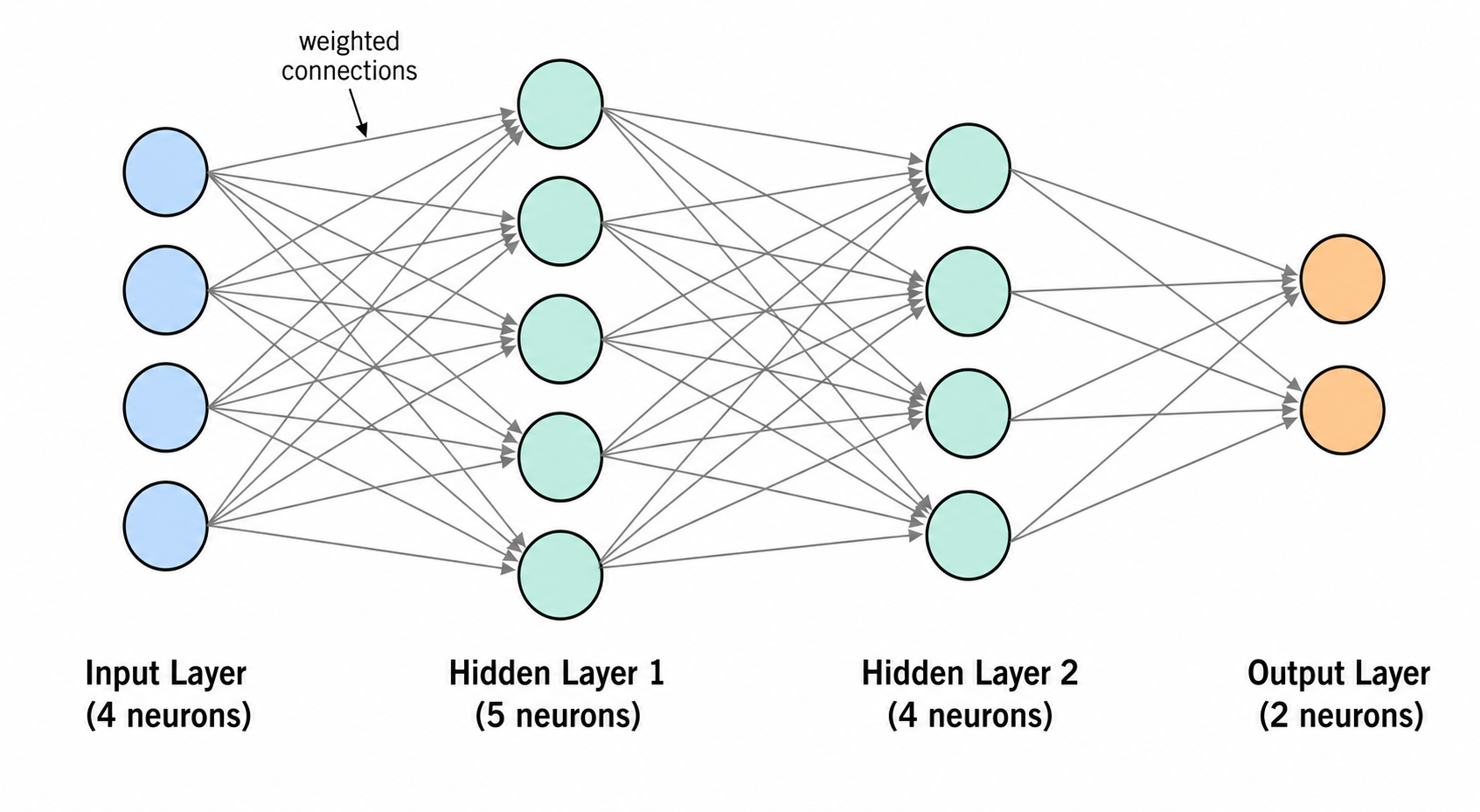
- 画一个全连接前馈网络(MLP),含一个输入层、两个隐藏层和一个输出层,展示神经元之间的密集连接,并标注每层的神经元数量。
- 画一个自编码器,含一个把输入压缩到瓶颈隐空间的编码器和一个对称地重建输入的解码器,标注压缩过程和隐空间维度。
- 画一个变分自编码器(VAE),展示编码器产出均值和方差、通过重参数化技巧采样的隐向量,以及解码器的重建。
- 画一个 GAN,含一个把噪声向量变成假样本的生成器和一个区分真假的判别器,并标注对抗训练环和两个损失信号。
- 画一个扩散模型的前向加噪过程和反向去噪过程,作为从左到右的流向,标注噪声调度和每个反向步骤中的 U-Net 去噪器。
端到端机器学习流程
一张干净的机器学习流程图展示的是整个系统,而不只是模型——非常适合论文或报告里的方法或系统概览图。
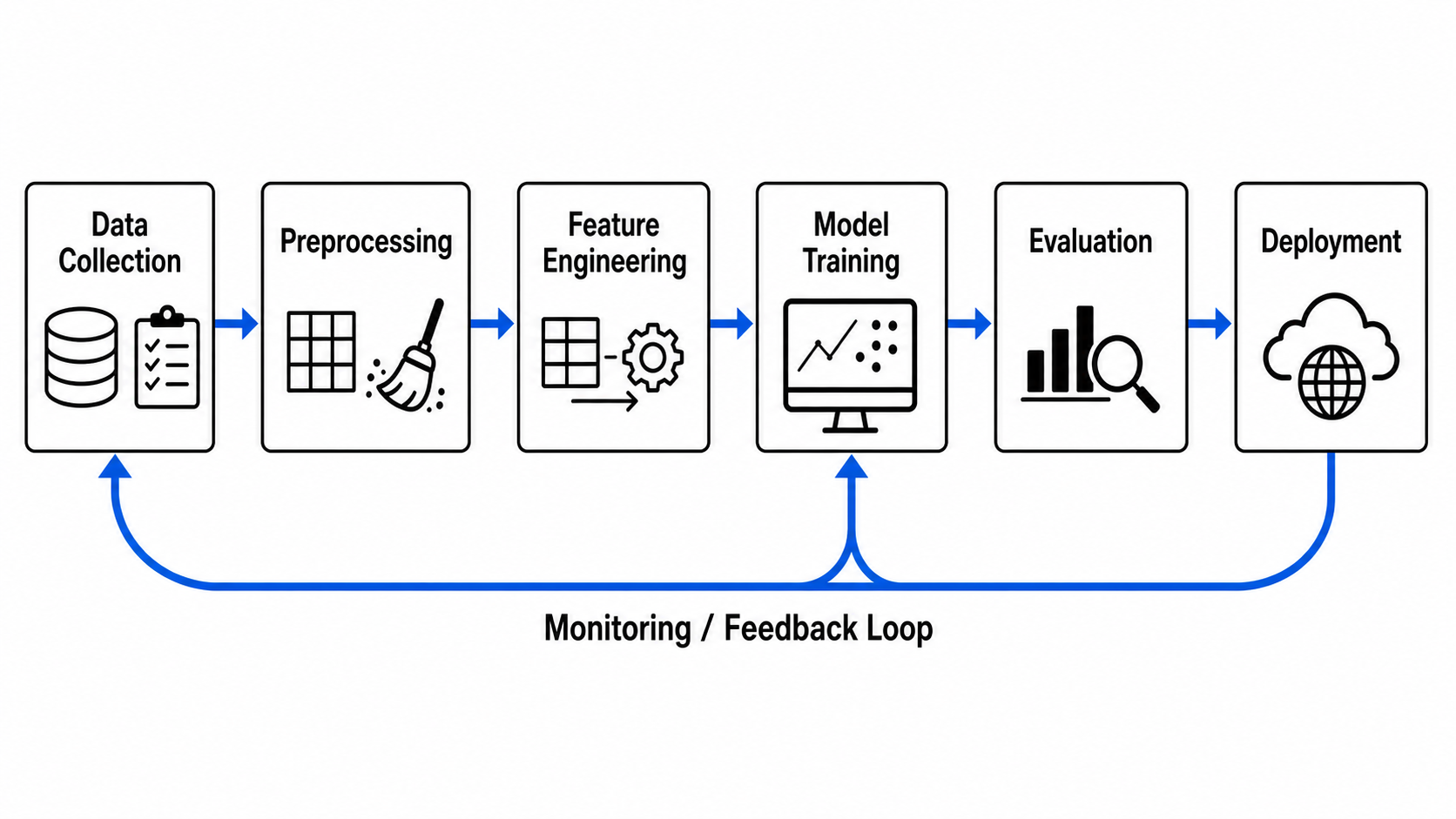
- 画一个端到端机器学习流程,作为从左到右的流向:数据采集、预处理、特征工程、模型训练、评估和部署,并带一条返回数据采集的监控反馈环,每个阶段都标注。
- 画一个 RAG(检索增强生成)系统:用户查询、嵌入步骤、对向量数据库的检索器、检索到的上下文,以及一个生成有据可依答案的 LLM,从左到右排布。
- 画一个 MLOps 生命周期作为一个环:数据版本管理、实验跟踪、模型训练、CI/CD、部署和监控,并由漂移检测触发重训练。
- 画一个模型服务架构:客户端请求打到负载均衡器、一个带批处理的推理服务器、一个 GPU 模型副本,以及一个特征存储,并标注时延。
常见错误(及修正方法)
- 模块未标注或标注错误。 修正:在提示词里列出确切名称("标注 conv1、pool1、fc1、softmax")。用"把 'attetion' 改成 'multi-head attention'"重新生成。
- 张量维度缺失或错误。 修正:明确要求"标注每一阶段的特征图尺寸",并给出输入维度,让整条链保持一致。
- 数据流含糊。 修正:要求"带箭头的从左到右数据流",这样读者就知道张量往哪个方向走。
- 文字乱码(通用图像 AI 的典型问题)。修正:SciDraw AI 能渲染干净的无衬线标签——若某个词看起来不对,把确切措辞重新生成一次。
- 堆叠过于拥挤。 修正:要求"把重复的模块折叠成一个标注 ×N 的模块"或把图拆成多个面板。
导出并使用你的架构图
图做好后,可导出为可编辑 SVG 或 PowerPoint(PPTX),或下载高分辨率图像用于稿件、幻灯片或海报。需要改某个层名、更正一个拼写错误或翻译标签?参见如何编辑 AI 配图中的文字和标签。需要换一套配色——为符合期刊风格或为色盲友好?参见如何为科研示意图重新配色。
常见问题
最好的神经网络结构图生成器是哪个? SciDraw AI 的神经网络结构图生成器专为论文可用的深度学习架构图打造——CNN、Transformer、RNN/LSTM、MLP、U-Net、GAN 和机器学习流程——配干净的带标注模块、张量维度和可编辑的 SVG/PPTX 导出。
怎么用 AI 画一张 CNN 架构图? 按顺序描述各层(输入 → 卷积/池化堆叠 → 展平 → 全连接 → softmax),并要求在每一阶段标出特征图尺寸,然后生成。用上面的第 1 条提示词作为起点并微调标签。
可以免费在线画神经网络吗? 可以——你可以免费开始生成神经网络图,之后再升级以获得更多额度和可编辑的 SVG/PPTX 导出。
这是不是一个为论文做 Transformer 架构图的好方法? 是的。描述编码器/解码器堆叠、注意力和 Add-and-Norm 层,生成后导出为矢量格式,直接放进你的 LaTeX 或 Word 稿件。
这些配图准确到能用于发表吗? 它们以论文可用的输出为目标,但提交前请始终针对你具体的模型核对层顺序、维度和标签,并更正任何问题。
开始创作
挑选上面任意一条提示词,把它粘贴进神经网络结构图生成器,并在 SciDraw AI 编辑器中微调,直到它贴合你的模型。从一个简单的 MLP 到一个完整的 Transformer,你的下一张架构图只差一句话。


")
")