
벨 커브는 과학의 모든 분야에서 등장합니다. 시험 점수, 측정 오차, 생물학적 특성, 통계 분석 등 데이터가 중심값 주변에 모이는 현상을 시각화할 때 가장 많이 쓰이는 그래프입니다. 그러나 깔끔하게 레이블이 붙은 정규분포 그래프를 만들려면 생각보다 많은 시간이 걸리곤 합니다.
이 가이드는 벨 커브를 만드는 방법을 수학적 원리부터 Excel·Google Sheets 실습, 그리고 AI 도구를 활용한 빠른 방법까지 단계별로 안내합니다.
이 글에서 배울 내용:
- 평균과 표준편차가 벨 커브에서 실제로 무엇을 제어하는지
- 68–95–99.7 법칙과 그 의미
- Excel과 Google Sheets 단계별 작성법
- 표준편차 구간과 z-점수 레이블 추가 방법
- 주요 정규분포 값 빠른 참조표
- SciDraw AI 벨 커브 생성기로 몇 초 만에 완성하는 방법
벨 커브란 무엇인가
벨 커브는 정규분포를 시각적으로 나타낸 것입니다. 정규분포는 두 개의 매개변수만으로 완전히 정의되는 좌우 대칭의 단봉(unimodal) 확률분포입니다:
- 평균(μ): 곡선의 중심. 봉우리가 위치하는 지점
- 표준편차(σ): 데이터의 산포도. σ가 클수록 곡선은 넓고 납작해짐
곡선을 정의하는 확률밀도함수(PDF)는 다음과 같습니다:
f(x) = (1 / (σ√(2π))) × e^(-(x−μ)² / (2σ²))훌륭한 그래프를 만들기 위해 이 공식을 암기할 필요는 없지만, μ와 σ가 무엇을 하는지 이해하면 곡선을 올바르게 구성하고 레이블을 붙이는 데 도움이 됩니다.
평균과 표준편차가 곡선에 미치는 영향
| 매개변수 | 곡선에 미치는 영향 |
|---|---|
| μ 증가 | 곡선 전체가 오른쪽으로 이동 |
| μ 감소 | 곡선 전체가 왼쪽으로 이동 |
| σ 증가 | 곡선이 넓고 납작해짐 |
| σ 감소 | 곡선이 좁고 높아짐 |
| σ=1, μ=0 | 표준정규분포 |
핵심은 이것입니다: 형태는 항상 같은 종 모양이며, 위치와 크기만 달라집니다.
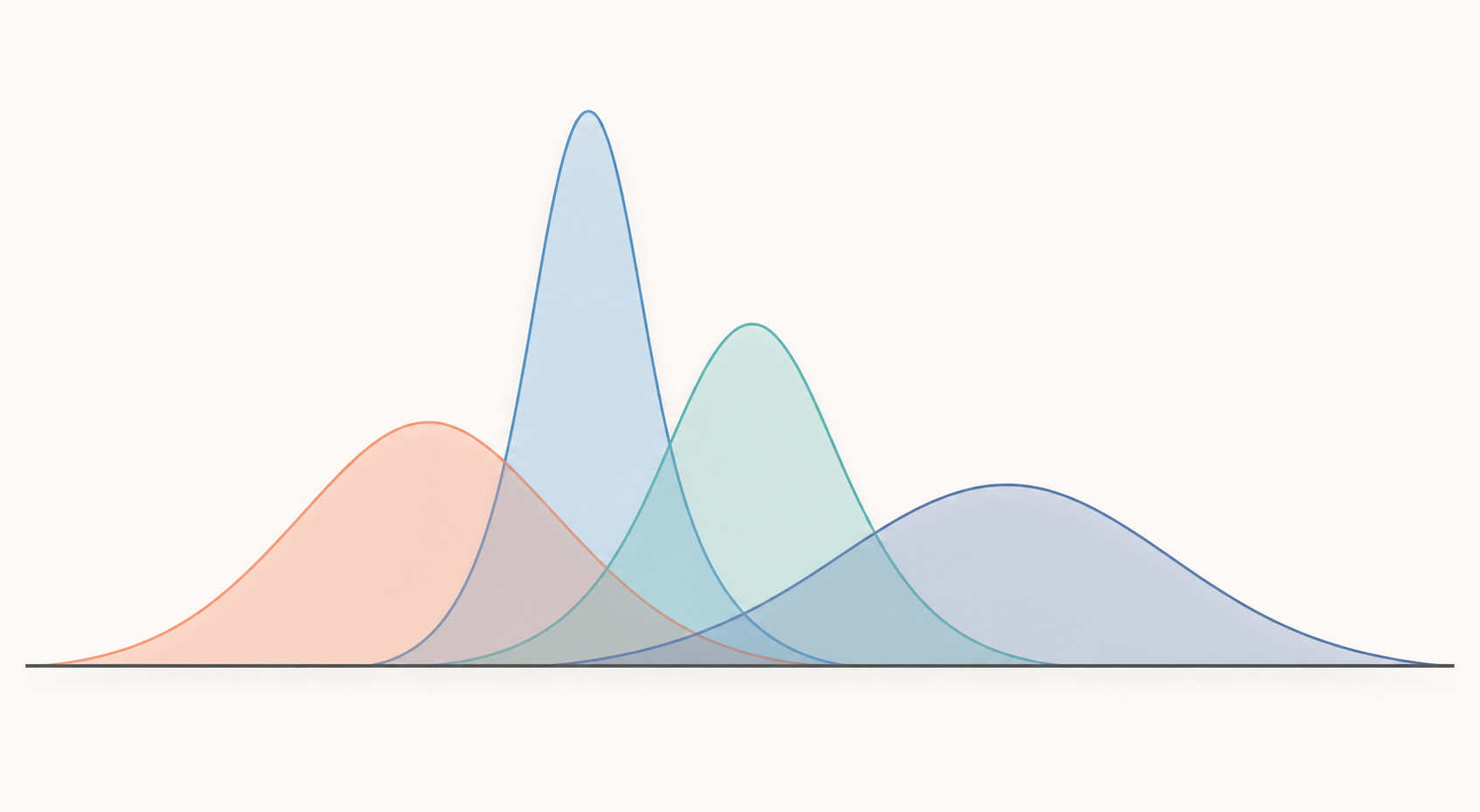 평균(μ)은 곡선을 좌우로 이동시키고, 표준편차(σ)는 곡선의 폭을 넓히거나 좁힙니다.
평균(μ)은 곡선을 좌우로 이동시키고, 표준편차(σ)는 곡선의 폭을 넓히거나 좁힙니다.
68–95–99.7 법칙
정규분포의 가장 유용한 성질 중 하나는 데이터가 평균 주변에 모이는 방식입니다:
| 구간 | 포함 비율 |
|---|---|
| μ ± 1σ | ≈ 68.27% |
| μ ± 2σ | ≈ 95.45% |
| μ ± 3σ | ≈ 99.73% |
| μ ± 4σ | ≈ 99.994% |
이 법칙을 활용하면 통계적 산포를 한눈에 전달할 수 있습니다. ±1σ, ±2σ, ±3σ 경계를 표시한 벨 커브는 독자에게 데이터 분포에 대한 즉각적인 직관을 제공합니다. 학술 논문, 교과서, 발표 자료에서 이런 표기를 자주 볼 수 있는 이유입니다.
z-점수
z-점수는 특정 값이 평균에서 몇 표준편차 떨어져 있는지를 나타냅니다:
z = (x − μ) / σ예를 들어 μ=100, σ=15(많은 IQ 검사의 설정)일 때, 점수 130의 z값은 2.0으로 +2σ 경계에 위치하며 상위 약 2.3%에 해당합니다.
z-점수 눈금(−3, −2, −1, 0, +1, +2, +3)으로 벨 커브에 레이블을 추가하면 논문 게재에 적합하고 독자 친화적인 그래프가 완성됩니다.
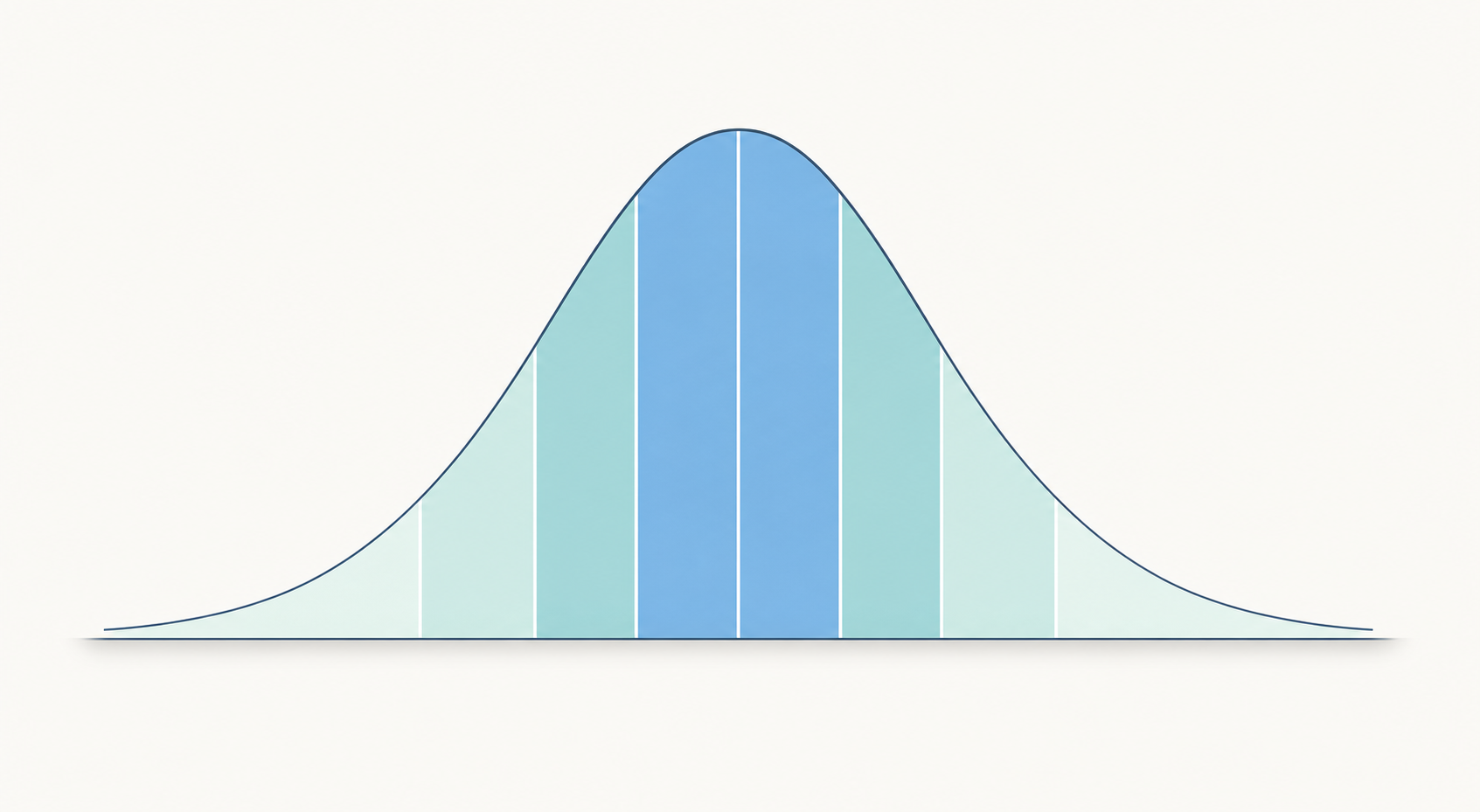 ±1σ(약 68%), ±2σ(약 95%), ±3σ(약 99.7%) 구간을 음영으로 나타낸 68–95–99.7 법칙 시각화.
±1σ(약 68%), ±2σ(약 95%), ±3σ(약 99.7%) 구간을 음영으로 나타낸 68–95–99.7 법칙 시각화.
Excel에서 벨 커브 만들기
1단계: 매개변수 설정
빈 시트에서 평균과 표준편차를 두 셀에 입력합니다(예: B1=0, B2=1, 표준정규분포 기준).
2단계: X축 값 생성
A열에서 평균으로부터 ±4σ 범위를 커버하는 x값 수열을 생성합니다. μ=0, σ=1이면 −4부터 +4까지 작은 간격으로(0.1 간격, 81행) 값을 만듭니다.
- A1:
−4 - A2:
=A1+0.1 - A81(4.0)까지 아래로 드래그
3단계: 정규분포 PDF 값 계산
B열에 정규분포 Excel 함수를 입력합니다:
=NORM.DIST(A1,$B$1,$B$2,FALSE)A1= x값$B$1= 평균(절대 참조)$B$2= 표준편차(절대 참조)FALSE= PDF(누적 아님)
모든 x값에 맞게 수식을 아래로 드래그합니다.
4단계: 꺾은선형 차트 삽입
- A열과 B열을 선택합니다(x와 y 데이터).
- 삽입 → 차트 → 꺾은선형 차트("곡선형 꺾은선"을 선택하면 깔끔한 종 모양이 됩니다).
- Excel이 X축에 x값, Y축에 PDF 값을 표시합니다.
5단계: 표준편차 구간 레이블 추가
±1σ, ±2σ, ±3σ 경계를 표시하려면 세로 점선을 추가합니다:
- −3, −2, −1, 0, 1, 2, 3의 x값과 해당 PDF 값이 담긴 보조 테이블을 만듭니다(
NORM.DIST재사용). - 이를 두 번째 데이터 계열로 추가합니다(유형: 점과 선이 있는 분산형).
- 해당 선을 점선으로 서식 지정하고 "−1σ", "+1σ" 등의 데이터 레이블을 추가합니다.
또는 음영 처리된 영역 계열을 사용하여 68%, 95%, 99.7% 구간에 색상을 입힐 수 있습니다. 시각적으로 더 인상적이지만 추가 데이터 열이 몇 개 필요합니다.
6단계: 차트 마무리
- 격자선을 제거해 깔끔한 외관 유지.
- Y축 최솟값을 0으로 설정.
- 차트 제목과 축 레이블 추가.
- PNG 또는 SVG로 내보내 문서에 사용.
Google Sheets에서 벨 커브 만들기
과정은 Excel과 거의 동일합니다.
1~2단계: Excel과 동일
매개변수를 설정하고 A열에 −4부터 +4까지 0.1 간격으로 x값을 생성합니다.
3단계: NORMDIST 함수 사용
Google Sheets는 함수명이 약간 다릅니다:
=NORMDIST(A1,평균,표준편차,FALSE)평균과 표준편차를 셀 참조로 바꿔주세요(예: $D$1, $D$2).
4단계: 곡선형 꺾은선 차트 삽입
- 두 열을 선택합니다.
- 삽입 → 차트.
- 차트 편집기에서 곡선형 꺾은선 차트를 선택합니다.
- A열을 X축으로 설정합니다.
5단계: 레이블 추가 및 내보내기
Google Sheets의 차트 커스터마이즈 기능은 Excel보다 제한적이지만:
- 차트 편집기에서 수동으로 텍스트 주석을 추가할 수 있습니다.
- 차트 메뉴에서 PNG 또는 SVG로 다운로드할 수 있습니다.
저널 수준의 고품질 그림이 필요하다면 Google Sheets 내보내기 결과를 전문 도구에서 다듬는 것이 좋습니다.
빠른 참조: 정규분포 주요 수치
| x(z-점수) | 누적 확률 | 이 값 이하 데이터 비율 |
|---|---|---|
| −3.0 | 0.0013 | 0.13% |
| −2.0 | 0.0228 | 2.28% |
| −1.0 | 0.1587 | 15.87% |
| 0.0 | 0.5000 | 50.00% |
| +1.0 | 0.8413 | 84.13% |
| +2.0 | 0.9772 | 97.72% |
| +3.0 | 0.9987 | 99.87% |
각 z-점수 경계에 정확한 확률 레이블을 표시할 때 이 표를 활용하세요.
Excel vs. Google Sheets vs. AI 도구: 비교
| 방법 | 속도 | 커스터마이즈 | 내보내기 품질 | 학습 난이도 |
|---|---|---|---|---|
| Excel | 보통 | 높음 | 양호(PNG/SVG) | 보통 |
| Google Sheets | 보통 | 보통 | 무난(PNG) | 낮음~보통 |
| Python(matplotlib) | 느림(환경 설정 필요) | 매우 높음 | 우수(PDF/SVG) | 높음 |
| SciDraw AI | 빠름 | 양호 | 우수 | 매우 낮음 |
차트 편집기와 씨름하거나 코드를 작성하지 않고도 깔끔하게 레이블이 붙은 벨 커브가 빠르게 필요한 연구자라면, AI 기반 과학 그림 제작기가 대부분의 번거로움을 해결해 줍니다.
더 빠른 방법: SciDraw AI로 벨 커브 만들기
Excel에서 레이블이 제대로 붙은 벨 커브를 만들려면 20~30분이 걸립니다. x값 생성, PDF 공식 입력, 표준편차 구간 보조 계열 생성, 축 서식 지정 등 수동 작업이 금방 쌓입니다.
SciDraw AI 벨 커브 생성기는 자연어로 필요한 그림을 설명하면 몇 초 안에 정확하게 서식이 지정되고 레이블이 붙은 정규분포 그래프를 생성합니다. 지정 가능한 옵션:
- 평균과 표준편차 값
- 음영 처리할 표준편차 구간(±1σ, ±2σ, ±3σ)
- z-점수 레이블
- 색상 구성 및 스타일(논문용 또는 발표용)
결과물은 바로 다운로드해서 논문, 슬라이드, 보고서에 삽입할 수 있는 깔끔한 과학 그림입니다.
여러 통계 그림을 제작하는 팀이라면 과학 그림 제작기가 정규분포 곡선 외에도 히스토그램, 상자그림, 산점도 등을 텍스트 입력만으로 처리해 드립니다.
 평범한 자연어 프롬프트를 SciDraw AI가 레이블이 깔끔하게 붙은 벨 커브 그림으로 변환합니다.
평범한 자연어 프롬프트를 SciDraw AI가 레이블이 깔끔하게 붙은 벨 커브 그림으로 변환합니다.
자주 묻는 질문
Q: 벨 커브와 히스토그램의 차이점은 무엇인가요? A: 히스토그램은 실제 관측된 데이터의 빈도를 이산적인 막대로 표시합니다. 벨 커브(정규분포)는 이론적인 확률밀도함수입니다. 히스토그램 위에 벨 커브를 겹쳐 그리면 데이터가 정규분포에 얼마나 잘 맞는지 시각적으로 확인할 수 있습니다.
Q: 평균과 표준편차를 어떻게 결정해야 하나요?
A: 데이터셋의 실제 평균과 표준편차를 사용하세요(Excel/Sheets에서 AVERAGE와 STDEV로 계산). 실제 데이터가 아닌 개념 설명 목적이라면 μ=0, σ=1의 표준정규분포를 사용하는 것이 일반적입니다.
Q: 실제 데이터 포인트를 곡선에 표시할 수 있나요? A: 네. 곡선을 그린 후, 개별 데이터 포인트의 x값과 y=0(또는 약간의 오프셋)으로 분산형 계열을 추가하면 각 관측값이 분포에서 어느 위치에 있는지 확인할 수 있습니다.
Q: 부드러운 곡선을 위해 X축 포인트가 몇 개 필요한가요? A: ±4σ 범위에 최소 50~80개 포인트가 있으면 대부분의 차트 도구에서 부드럽게 보입니다. 0.1σ 간격이 신뢰할 수 있는 기본값입니다.
Q: 데이터가 벨 커브에 맞지 않으면 무엇을 의미하나요? A: 왜도(비대칭 분포), 복수 하위집단(이봉분포), 또는 이상값이 있을 수 있습니다. 많은 통계 검정이 정규성을 가정하므로 적용하기 전에 분포 적합성을 확인하는 것이 중요합니다.
Q: 정규분포와 가우스 분포는 같은 건가요? A: 네. "정규분포", "가우스 분포", "벨 커브"는 모두 같은 확률분포를 가리킵니다. "가우스 분포"는 물리학과 공학에서 더 많이 쓰이는 표현이며, "정규분포"는 통계학의 표준 용어입니다.

 만드는 법: 예시로 배우는 단계별 가이드")
")
")