
체계적 문헌고찰이나 메타분석을 학술지에 투고해 본 경험이 있다면 PRISMA 흐름도 제출을 요청받은 적이 있을 것입니다. 근거 합성 연구에서 가장 널리 쓰이는 그림으로, 명확하게 라벨링된 4개 단계, 문헌 수 열, 그리고 수천 건의 데이터베이스 검색 결과가 최종 분석 대상 연구로 좁혀지는 과정을 보여주는 화살표로 구성됩니다.
보편적으로 쓰이는 양식임에도 불구하고, 처음 접하는 연구자들은 혼란스러워하는 경우가 많습니다. 어느 박스에 어떤 숫자를 넣어야 할까요? '식별된 레코드'와 '검색된 보고서'는 무슨 차이일까요? '다른 방법' 열은 언제 추가해야 할까요? 이 가이드에서 이 모든 질문에 답하고, 완성도 있는 PRISMA 2020 흐름도를 처음부터 단계별로 작성하는 방법을 안내합니다.
이 가이드에서 배울 내용:
- PRISMA 2020 흐름도의 4단계와 각 단계의 의미
- 각 박스에 기재해야 할 구체적인 숫자
- 데이터베이스 검색과 기타 식별 방법의 처리 방법
- 심사자의 수정 요청을 부르는 흔한 실수
- SciDraw AI PRISMA 흐름도 생성기로 완성본을 빠르게 만드는 방법
PRISMA가 생긴 이유와 흐름도의 중요성
PRISMA는 Preferred Reporting Items for Systematic Reviews and Meta-Analyses(체계적 문헌고찰 및 메타분석을 위한 우선 보고 항목)의 약자입니다. 2020년 개정판은 2009년 버전을 대체하면서 레코드 출처(데이터베이스, 등록기관, 인용 문헌, 기타 방법)에 관한 표현을 명확히 하고, 전문 보고서를 검색·취득하는 단계를 명시적으로 추가했습니다.
흐름도는 The BMJ, The Lancet, JAMA, Cochrane Database of Systematic Reviews를 비롯한 수백 개의 학술지에서 필수 또는 강력 권고 사항입니다. 의학, 심리학, 교육학, 사회과학 분야 학술지 대부분이 해당됩니다. 심사자는 투고 원고를 받으면 흐름도를 가장 먼저 확인합니다. 숫자가 맞지 않거나 박스가 빠져 있으면 '대폭 수정(major revision)' 판정을 받는 가장 빠른 경로 중 하나입니다.
PRISMA 2020의 4단계 이해하기
PRISMA 2020은 문헌 검색 과정을 4개의 순차적 단계로 정리합니다. 위가 넓고 아래가 좁은 깔때기 모양으로 생각하면 됩니다.
| 단계 | 쉬운 설명 |
|---|---|
| 식별(Identification) | 어떤 필터도 적용하기 전에 발견된 모든 레코드 |
| 선별(Screening) | 제목/초록 수준에서 포함·제외 기준으로 검토한 레코드 |
| 적격성(Eligibility) | 취득해 상세하게 평가한 전문 보고서 |
| 포함(Included) | 모든 기준을 통과해 합성에 포함된 연구 |
각 단계에는 해당 단계에 진입한 레코드 수와 제외된 레코드 수(이유 포함)를 보여주는 박스가 하나 이상 있습니다.
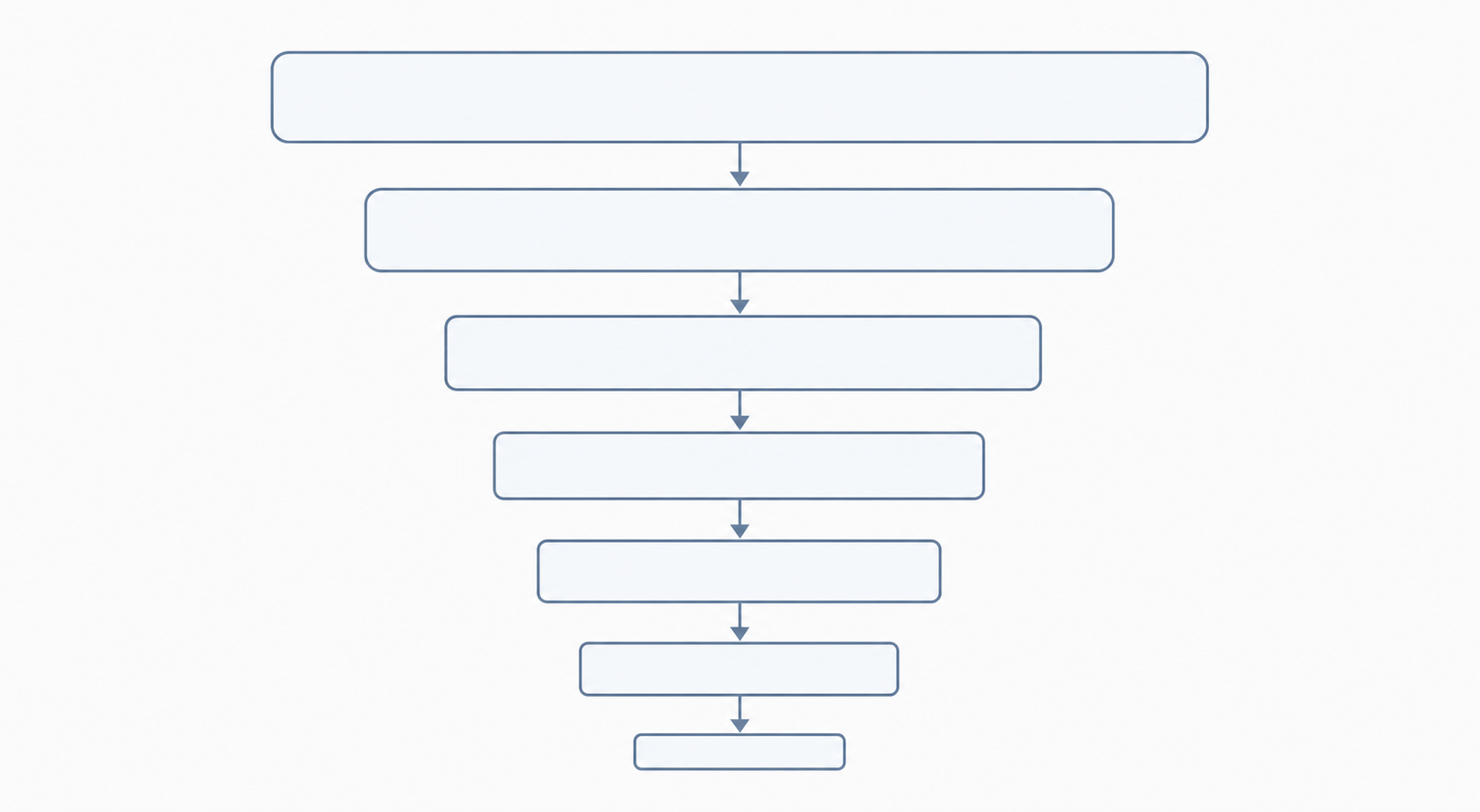 PRISMA 흐름은 깔때기처럼 작동하여, 검색된 모든 레코드에서 최종적으로 포함된 연구로 좁혀집니다.
PRISMA 흐름은 깔때기처럼 작동하여, 검색된 모든 레코드에서 최종적으로 포함된 연구로 좁혀집니다.
1단계 — 식별
2열 구조
PRISMA 2020의 식별 단계는 두 개의 열로 나뉩니다:
- 왼쪽 열 — 데이터베이스 및 등록기관: 문헌 데이터베이스(PubMed, Embase, Web of Science, Cochrane CENTRAL, PsycINFO, Scopus 등)와 임상시험 등록기관(ClinicalTrials.gov, WHO ICTRP 등)에서 검색된 레코드.
- 오른쪽 열 — 기타 방법: 인용 문헌 검색(역방향·순방향), 저자 연락, 회색 문헌 검토 또는 데이터베이스 이외의 기타 출처에서 발견된 레코드.
데이터베이스만 검색했다면 오른쪽 열을 완전히 생략할 수 있습니다. 두 방법 모두 사용했다면 양쪽을 모두 표시합니다.
각 식별 박스에 기재할 내용
왼쪽 열, 박스 1:
데이터베이스에서 식별된 레코드(n = X) 및 등록기관(n = Y)
중복 제거 전에 모든 데이터베이스 검색 결과를 하나의 숫자로 합산합니다. PubMed에서 1,243건, Embase에서 2,187건이 검색되었다면 중복이 있더라도 합계는 3,430건입니다.
왼쪽 열, 박스 2(제거):
선별 전 제거된 레코드: 중복 레코드 제거(n = ?) 자동화 도구에 의해 부적격 표시된 레코드(n = ?) 취득되지 않은 레코드(n = ?)
각 이유를 별도로 나열합니다. '자동화 도구'는 인적 선별 전에 사용된 기계학습 기반 선별 소프트웨어(Rayyan, Covidence 등)를 의미합니다.
오른쪽 열(해당하는 경우):
식별된 레코드 출처: 인용 문헌 검색(n = ?) / 웹사이트(n = ?) / 기관(n = ?) / 수기 검색(n = ?) / 기타 방법(n = ?)
방법별로 세분화하거나 '기타 방법' 합계로 묶어도 됩니다.
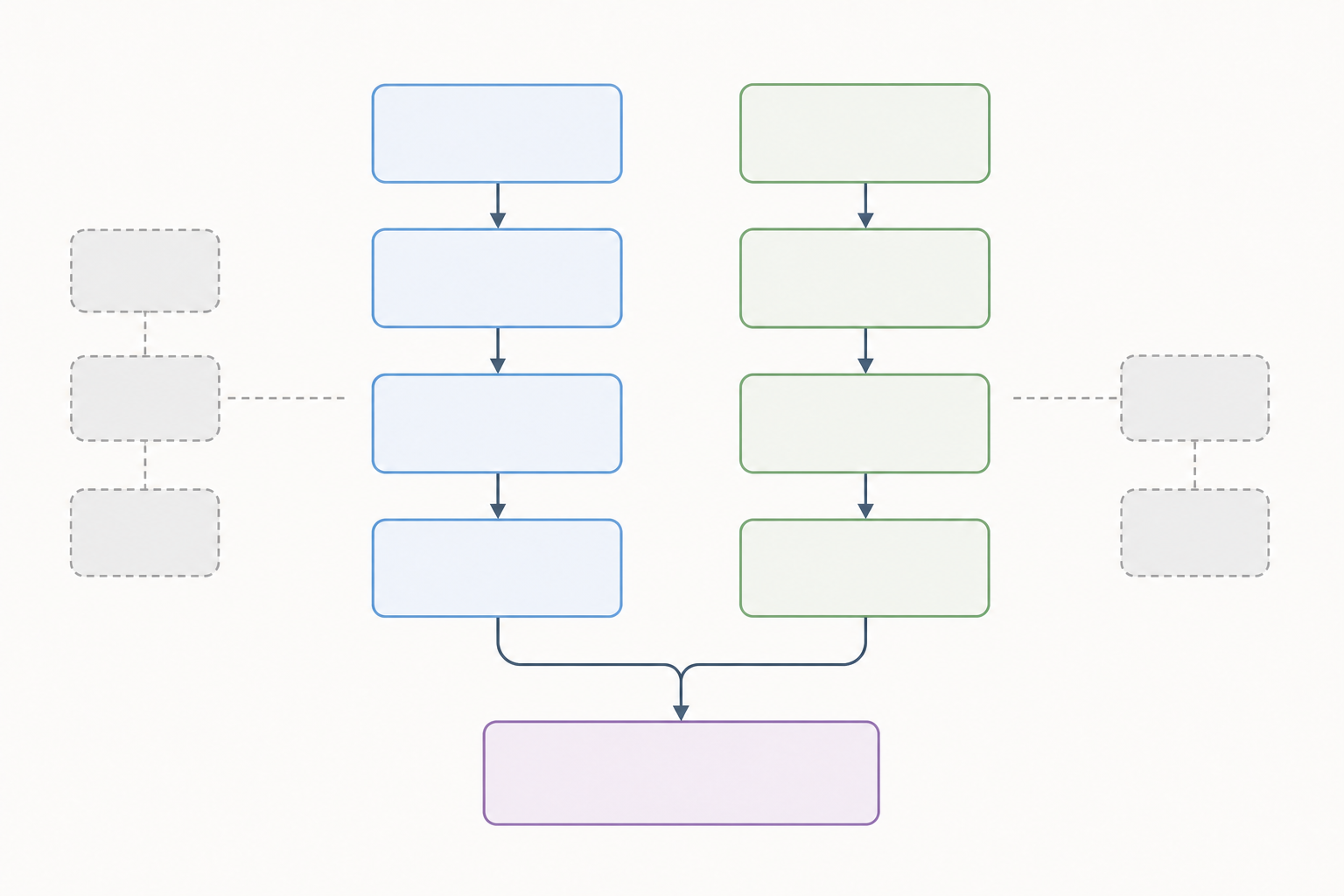 식별 단계는 2열 구조를 사용합니다——한쪽은 데이터베이스와 등록기관, 다른 쪽은 기타 방법입니다.
식별 단계는 2열 구조를 사용합니다——한쪽은 데이터베이스와 등록기관, 다른 쪽은 기타 방법입니다.
2단계 — 선별
중복 및 자동 제외 후 남은 레코드가 선별 단계로 넘어갑니다.
박스: 선별된 레코드
사람이 실제로 검토한(제목 및 초록) 레코드의 총수입니다. 식별된 레코드에서 선별 전 제거된 레코드를 뺀 값과 같습니다.
선별된 레코드(n = ?)
박스: 제외된 레코드
제목/초록 수준에서 제외된 합계를 기재합니다. PRISMA 2020은 제목/초록 제외 이유를 나열할 것을 요구하지 않습니다(전문 제외와 다름). 합계만 있으면 됩니다.
제외된 레코드(n = ?)
3단계 — 적격성(전문 평가)
제목/초록 선별을 통과한 레코드는 전문 취득 및 평가 단계로 이동합니다.
박스: 취득을 시도한 보고서
전문 취득을 시도한 레코드 수입니다. 보통 선별에서 '제외되지 않은' 레코드 수와 동일하지만, 가끔 취득 가능한 전문이 없는 경우도 있습니다.
취득 시도된 보고서(n = ?)
박스: 취득되지 않은 보고서
취득하지 못한 전문(유료 장벽 + 저자 무응답, 학술대회 초록만 있는 경우 등)의 수입니다.
취득되지 않은 보고서(n = ?)
박스: 적격성 평가를 받은 보고서
실제로 읽고 모든 기준에 따라 평가한 전문의 수입니다.
적격성 평가를 받은 보고서(n = ?)
박스: 이유 포함 제외된 보고서
흐름도에서 가장 중요한 제외 박스입니다. 각 제외 이유와 해당 건수를 반드시 나열해야 합니다. 주요 이유는 다음과 같습니다:
- 대상 집단이 기준을 충족하지 않음
- 중재/노출이 연구 범위 밖
- 비교군 미지정
- 결과(아웃컴) 미보고
- 연구 설계 부적합
- 중복 출판(다른 포함 연구와 동일 데이터)
- 학술대회 초록만 있거나 완전한 데이터 없음
제외된 보고서: 이유 A(n = ?) 이유 B(n = ?) ……
4단계 — 포함
박스: 고찰에 포함된 신규 연구
전문 평가를 통과해 고찰에 포함된 연구입니다. 메타분석을 수행하는 경우, 적어도 하나의 분석에 데이터를 제공하는 연구가 해당됩니다.
고찰에 포함된 연구(n = ?)
박스: 포함된 신규 연구의 보고서
하나의 '연구'가 여러 보고서를 가질 수 있습니다(주 논문, 이차 결과 논문, 프로토콜 논문 등). 고유 연구 수와 보고서 총수를 모두 기록합니다.
포함된 신규 연구의 보고서(n = ?)
이전 연구(선행 고찰 업데이트의 경우)
이번 체계적 문헌고찰이 이전 버전의 업데이트인 경우, PRISMA 2020은 이전 버전에서 이월된 연구 및 보고서 박스를 추가합니다. 이것은 포함 단계 하단의 음영 처리된 영역에 표시됩니다.
박스 및 건수 완전 참조표
| 박스 라벨 | 숫자가 나타내는 것 | 계산 확인 |
|---|---|---|
| 데이터베이스 및 등록기관의 레코드 | 중복 제거 전 모든 데이터베이스 검색 결과 | 개별 데이터베이스 검색 결과의 합 |
| 기타 방법의 레코드 | 데이터베이스 이외의 모든 레코드 | 방법 유형별 합계 |
| 선별 전 제거된 레코드 | 중복 + 자동 제외 + 미취득의 합 | 식별 합계에서 차감 |
| 선별된 레코드 | 사람이 검토한 레코드 | 식별 합계 − 선별 전 제거 수 |
| 제외된 레코드(제목/초록) | 제목/초록 선별 탈락 | 선별 수 − 전문으로 넘어간 수 |
| 취득 시도된 보고서 | 전문을 취득하려 한 레코드 | = 선별 단계에서 넘어온 레코드 |
| 취득되지 않은 보고서 | 접근 불가한 전문 | 시도 수 − 실제 취득 수 |
| 적격성 평가를 받은 보고서 | 실제로 읽은 전문 | = 취득된 보고서 |
| 제외된 보고서(이유 포함) | 전문 평가 탈락 | 평가 수 − 포함 수; 이유별 합계가 총 제외 수와 일치해야 함 |
| 포함된 연구 | 합성에 포함된 고유 연구 | 최종 분석 표본 |
| 포함된 연구의 보고서 | 포함 연구의 총 출판물 수 | 연구 수 이상 |
숫자의 일관성 확인
숫자 불일치는 심사자 수정 요청의 가장 흔한 원인 중 하나입니다. 투고 전 다음 네 가지를 확인하세요:
- 식별→선별: (데이터베이스 레코드) + (기타 방법 레코드) − (선별 전 제거 수) = 선별된 레코드
- 선별→적격성: 선별된 레코드 − 제외된 레코드(제목/초록) = 취득 시도된 보고서
- 적격성→포함: 평가된 보고서 − 제외된 보고서(이유 포함) = 포함된 연구
- 보고서 수 ≥ 연구 수: 포함된 연구의 보고서 수는 포함된 연구 수 이상이어야 합니다
어떤 숫자든 수정할 때마다 이 네 가지를 다시 확인하세요.
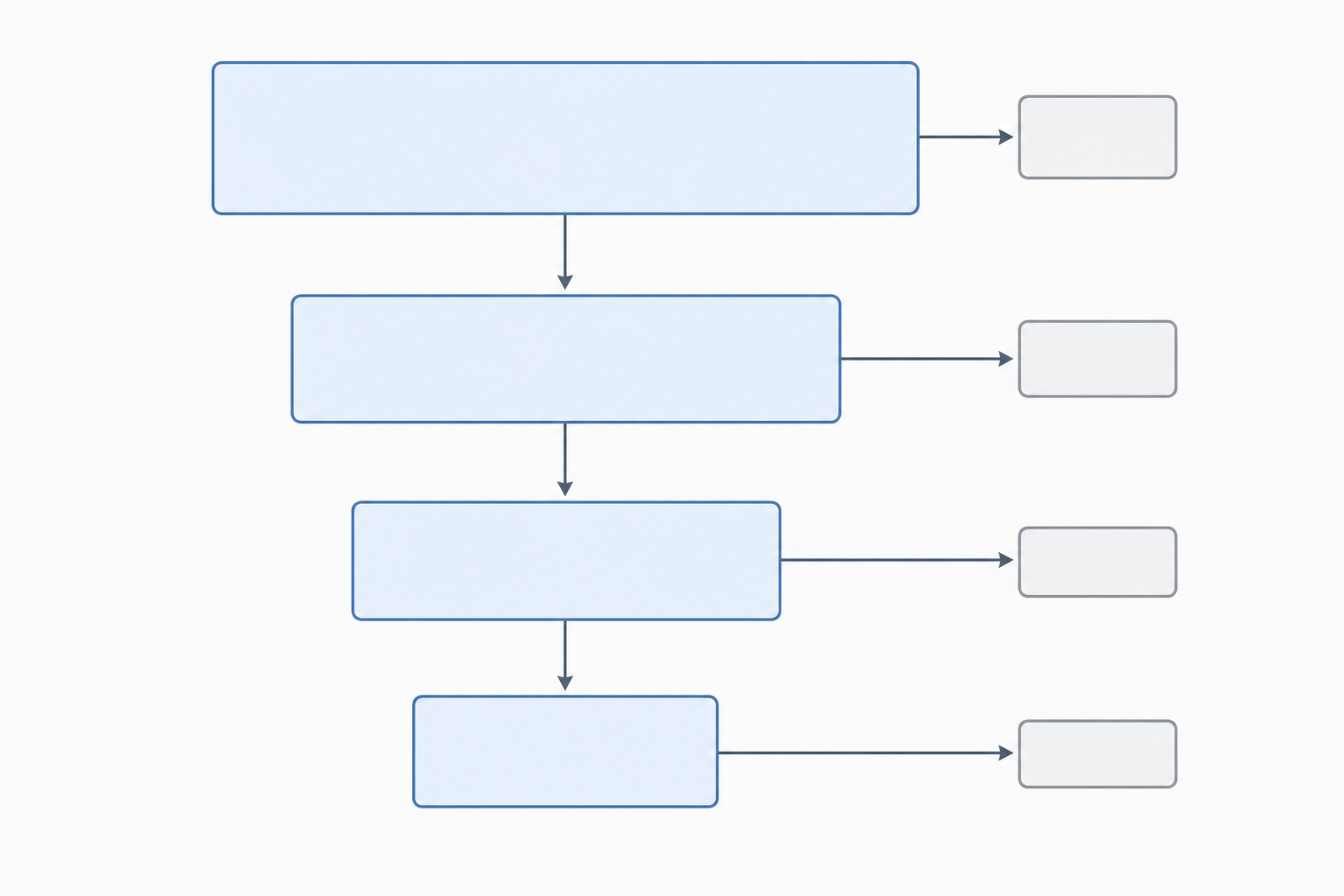 모든 단계에서 숫자는 맞아떨어져야 합니다. 들어온 레코드에서 제외된 것을 빼면 다음 단계로 넘어가는 레코드가 됩니다.
모든 단계에서 숫자는 맞아떨어져야 합니다. 들어온 레코드에서 제외된 것을 빼면 다음 단계로 넘어가는 레코드가 됩니다.
자주 하는 실수와 예방법
첫 번째 박스에 중복 제거 후 수를 기재한다. 식별 단계의 첫 번째 박스에는 중복 제거 전 각 출처의 원시 합계를 기재해야 합니다. 중복 제거 단계는 제거 박스에 별도로 표시됩니다.
전문 제외 이유를 생략한다. 제목/초록 제외 이유는 선택 사항이지만, 전문 제외 이유는 필수입니다. 모든 이유와 건수를 나열하세요.
연구와 보고서를 혼동한다. 포함 단계에서는 고유 연구 수와 이를 보고하는 출판물 수를 구분합니다. 두 가지를 분리해서 관리하세요.
다른 검색을 수행했음에도 오른쪽 열을 표시하지 않는다. 학술지 수기 검색, 참고문헌 목록 선별, 전문가 연락을 수행했다면 해당 레코드는 오른쪽 열에 포함되어야 합니다. 생략하면 보고 편향으로 지적받습니다.
2020년 투고에 PRISMA 2009 템플릿을 사용한다. 두 버전은 비슷해 보이지만 용어와 구조가 다릅니다. 대부분의 학술지는 현재 2020년 버전을 요구합니다. 확실하지 않다면 Page 등(2021년, BMJ)의 PRISMA 2020 성명서를 참조하세요.
흐름도 서식
PRISMA는 글꼴이나 색상을 규정하지 않지만, 관례와 가독성을 위한 몇 가지 권고 사항이 있습니다:
| 요소 | 권장 사항 |
|---|---|
| 글꼴 | 산세리프체(Arial, Helvetica, Calibri); 박스 텍스트는 8–10 pt |
| 박스 스타일 | 단계 박스는 둥근 직사각형; 건수/제거 박스는 일반 직사각형 |
| 화살표 | 단방향, 실선; 장식적 화살표 머리 없음 |
| 색상 | 흑백은 모든 학술지에서 안전; 제거 박스에 연한 회색 채우기는 가독성 향상 |
| 단계 라벨 | 굵게, 전체 대문자 또는 제목 형식; 각 단계의 첫 번째 박스 바깥 또는 위에 배치 |
| 파일 형식 | 학술지 투고에는 TIFF(300 DPI 이상) 또는 PDF; 프리프린트에는 PNG |
SciDraw AI로 PRISMA 흐름도 만들기
PowerPoint, Word, Illustrator에서 수동으로 흐름도를 그리는 작업은 번거롭습니다. 숫자가 바뀔 때마다 박스를 다시 편집하고 정렬을 확인해야 합니다. 전용 도구를 사용하면 훨씬 빠릅니다.
SciDraw AI의 PRISMA 흐름도 생성기는 구조화된 양식에 숫자를 직접 입력하면 올바르게 형식화된 출판 가능한 흐름도를 자동으로 생성합니다. 단계 라벨 조정, '기타 방법' 열 추가·삭제, 제외 이유 편집, 투고 학술지에서 요구하는 형식으로의 내보내기가 모두 가능합니다.
체계적 문헌고찰 외에도 실험 흐름, 분석 파이프라인, 다단계 방법론 다이어그램이 필요하다면 같은 플랫폼의 워크플로우 다이어그램 생성기를 활용할 수 있습니다. 원저 논문의 방법 섹션에도 유용합니다.
자주 묻는 질문
공식 PRISMA 2020 템플릿을 반드시 사용해야 하나요? PRISMA 웹사이트에서 기입 가능한 Word 템플릿을 제공하지만, 학술지에서 필수로 요구하는 것은 아닙니다. 필요한 요소와 정확한 건수가 포함된 흐름도라면 어떤 형식이든 허용됩니다. 전용 도구나 벡터 소프트웨어를 사용해도 체크리스트 내용과 일치한다면 괜찮습니다.
같은 레코드가 여러 데이터베이스에 나타나면 어떻게 계산하나요? 각 데이터베이스의 검색 결과에 한 번씩 계산합니다(첫 번째 박스의 중복 제거 전 합계에 기여). 이후 '중복 레코드 제거' 단계에서 하나를 제외한 나머지를 삭제합니다. 첫 번째 박스의 숫자가 원시 검색 결과를 반영하여 독자가 데이터베이스 간 중복도를 파악할 수 있도록 하는 것이 핵심입니다.
결과(아웃컴)별로 별도 PRISMA 흐름도가 필요한가요? 일반적으로 필요 없습니다. 하나의 흐름도가 전체 고찰을 커버합니다. 서로 다른 고찰 질문에 대해 별도 검색을 수행하는 경우에는 별도 흐름도가 적절할 수 있지만 드문 경우입니다. 공동 저자와 상의하고 학술지 투고 규정을 확인하세요.
스코핑 리뷰(Scoping Review)에도 PRISMA를 사용할 수 있나요? 스코핑 리뷰에는 PRISMA-ScR(PRISMA extension for Scoping Reviews)이라는 수정된 체크리스트가 있습니다. 흐름도 구조는 PRISMA 2020과 본질적으로 동일하므로 본 가이드의 박스 논리가 동일하게 적용됩니다.
제거 단계의 '자동화 도구'는 구체적으로 무엇을 가리키나요? 인적 선별 전에 기계학습이나 규칙 기반 알고리즘을 사용해 레코드를 관련 없을 가능성이 높다고 표시하는 소프트웨어입니다. 대표적인 예로 Rayyan의 AI 우선순위 지정, Covidence의 중복 제거 엔진, ASReview가 있습니다. 해당 도구를 사용하지 않았다면 제거 박스에서 그 줄을 생략하세요.
학술지에서 '연구 흐름도'를 요청했는데, 같은 건가요? 대부분의 경우 같습니다. '연구 흐름도', 'PRISMA 흐름도', '문헌 검색 플로우차트'는 모두 같은 그림을 가리킵니다. 학술지가 PRISMA 2020 준수를 명시적으로 요구한다면 이 가이드를 따르면 됩니다.

 검사 스트립 구조 모식도 그리는 법")
")
