
Chi ha mai sottoposto una revisione sistematica o una meta-analisi a una rivista si è quasi certamente sentito chiedere un diagramma di flusso PRISMA. È la figura più riconoscibile nella ricerca di sintesi delle evidenze: quattro fasi chiaramente etichettate, una colonna di conteggi e frecce che mostrano esattamente come si è passati da migliaia di risultati di banche dati a un gruppo ristretto di studi effettivamente analizzati.
Nonostante sia quasi universale, molti ricercatori trovano il diagramma confuso al primo incontro. Quali conteggi vanno in quale riquadro? Qual è la differenza tra «record identificati» e «report ricercati»? Quando si mostra una seconda colonna per «altri metodi»? Questa guida risponde a tutte queste domande e conduce passo dopo passo nella costruzione di un diagramma di flusso PRISMA 2020 completo e pronto per la pubblicazione.
Cosa imparerete:
- Le quattro fasi di un diagramma PRISMA 2020 e cosa significa ciascuna
- Esattamente quali numeri inserire in ogni riquadro
- Come gestire le ricerche nelle banche dati rispetto ad altri metodi di identificazione
- Gli errori più comuni che portano i revisori a richiedere correzioni
- Come produrre rapidamente la figura finale con il generatore di diagrammi di flusso PRISMA di SciDraw AI
Perché esiste PRISMA e perché il diagramma è importante
PRISMA è l'acronimo di Preferred Reporting Items for Systematic Reviews and Meta-Analyses (Elementi di segnalazione preferiti per revisioni sistematiche e meta-analisi). L'aggiornamento del 2020 ha sostituito la versione del 2009 e ha introdotto un linguaggio più chiaro sull'origine dei record (banche dati, registri, citazioni, altri metodi) e ha aggiunto un passaggio esplicito per la ricerca e il recupero dei report in testo completo.
Il diagramma di flusso è obbligatorio o fortemente raccomandato da centinaia di riviste, tra cui The BMJ, The Lancet, JAMA, Cochrane Database of Systematic Reviews e la maggior parte delle riviste di medicina, psicologia, scienze dell'educazione e scienze sociali. I revisori lo controllano immediatamente: un conteggio inconsistente o un riquadro mancante è uno dei modi più rapidi per ricevere una decisione di «revisione maggiore».
Comprendere le quattro fasi di PRISMA 2020
PRISMA 2020 organizza il processo di ricerca bibliografica in quattro fasi sequenziali. Si possono immaginare come un imbuto: largo in cima, stretto in fondo.
| Fase | Significato in termini semplici |
|---|---|
| Identificazione | Tutti i record trovati prima di applicare qualsiasi filtro |
| Selezione | Record verificati rispetto ai criteri di inclusione/esclusione a livello di titolo/abstract |
| Idoneità | Report in testo completo recuperati e valutati in dettaglio |
| Inclusi | Studi che hanno superato tutti i criteri e sono entrati nella sintesi |
Ogni fase ha uno o più riquadri che mostrano quanti record sono entrati e quanti sono stati rimossi (con le ragioni).
 Il flusso PRISMA funziona come un imbuto, restringendosi da tutti i record trovati agli studi infine inclusi.
Il flusso PRISMA funziona come un imbuto, restringendosi da tutti i record trovati agli studi infine inclusi.
Fase 1 — Identificazione
La struttura a due colonne
PRISMA 2020 divide l'identificazione in due colonne:
- Colonna sinistra — Banche dati e registri: record trovati ricercando nelle banche dati bibliografiche (PubMed, Embase, Web of Science, Cochrane CENTRAL, PsycINFO, Scopus, ecc.) e nei registri di trial (ClinicalTrials.gov, WHO ICTRP, ecc.).
- Colonna destra — Altri metodi: record trovati tramite ricerca per citazioni (a ritroso e in avanti), contatto con gli autori, revisione della letteratura grigia o qualsiasi altra fonte non basata su banche dati.
Se sono state cercate solo banche dati, la colonna destra può essere omessa interamente. Se sono stati usati entrambi, si mostrano entrambi.
Cosa inserire in ogni riquadro di identificazione
Colonna sinistra, riquadro 1:
Record identificati nelle banche dati (n = X) e nei registri (n = Y)
Combinare tutti i risultati delle banche dati in un unico numero prima della deduplicazione. Se PubMed ha restituito 1.243 record ed Embase 2.187, il totale è 3.430, anche se alcuni sono duplicati.
Colonna sinistra, riquadro 2 (rimozione):
Record rimossi prima della selezione: Record duplicati rimossi (n = ?) Record contrassegnati come non idonei da strumenti di automazione (n = ?) Record non recuperati (n = ?)
Elencare ciascuna ragione separatamente. Gli strumenti di automazione indicano qualsiasi software di selezione assistito dall'apprendimento automatico (Rayyan, Covidence, ecc.) utilizzato prima della selezione umana.
Colonna destra (se applicabile):
Record identificati da: Ricerca per citazioni (n = ?) / Siti web (n = ?) / Organizzazioni (n = ?) / Ricerca manuale (n = ?) / Altri metodi (n = ?)
Suddividere per metodo, o combinare in un unico totale «altri metodi» se più adatto alla rendicontazione.
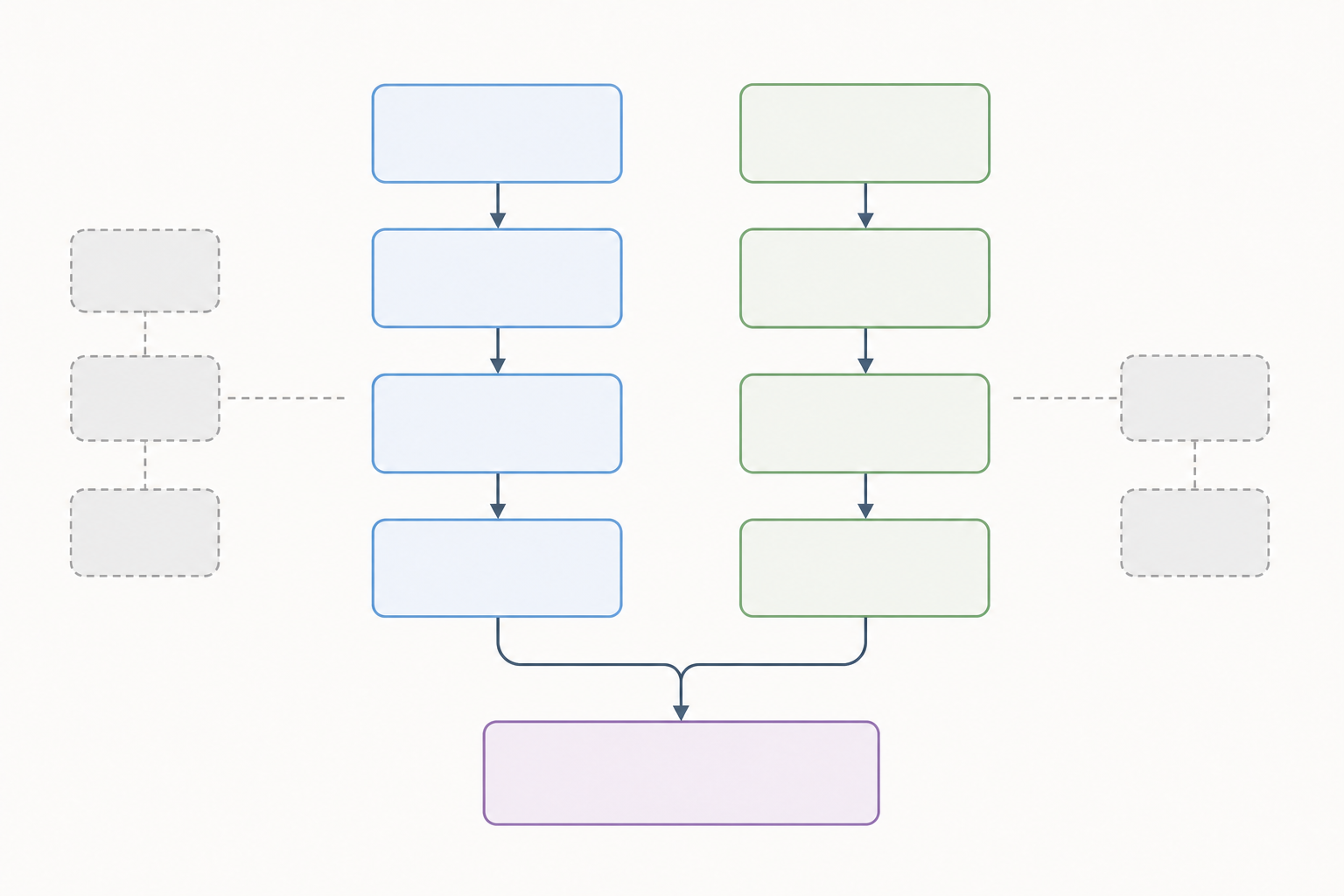 L'identificazione usa due colonne: banche dati e registri da un lato, altri metodi dall'altro.
L'identificazione usa due colonne: banche dati e registri da un lato, altri metodi dall'altro.
Fase 2 — Selezione
Dopo aver rimosso i duplicati e le esclusioni automatizzate, i record rimanenti entrano nella selezione.
Riquadro: Record selezionati
È il numero totale di record che un revisore umano ha effettivamente esaminato (titolo e abstract). È uguale a: record identificati meno record rimossi prima della selezione.
Record selezionati (n = ?)
Riquadro: Record esclusi
Riportare il totale escluso a livello di titolo/abstract. PRISMA 2020 non richiede di elencare le ragioni di esclusione per titolo/abstract (a differenza dell'esclusione del testo completo) — è sufficiente il totale.
Record esclusi (n = ?)
Fase 3 — Idoneità (Valutazione del testo completo)
I record sopravvissuti alla selezione per titolo/abstract passano al recupero e alla valutazione del testo completo.
Riquadro: Report ricercati per il recupero
È il conteggio dei record per i quali si è tentato di ottenere il testo completo. Di solito è identico ai record «non esclusi» dalla selezione, ma occasionalmente un record non ha un testo completo recuperabile.
Report ricercati per il recupero (n = ?)
Riquadro: Report non recuperati
Testi completi che non è stato possibile ottenere (dietro un paywall senza risposta dell'autore, solo abstract di conferenza, ecc.).
Report non recuperati (n = ?)
Riquadro: Report valutati per l'idoneità
I testi completi effettivamente letti e valutati rispetto a tutti i criteri.
Report valutati per l'idoneità (n = ?)
Riquadro: Report esclusi con le ragioni
Questo è il riquadro di esclusione più importante. È obbligatorio elencare ciascuna ragione di esclusione e il suo conteggio. Le ragioni più comuni includono:
- La popolazione non soddisfa i criteri
- Intervento/esposizione al di fuori del campo di applicazione
- Comparatore non specificato
- Esito non riportato
- Disegno di studio errato
- Pubblicazione duplicata (stessi dati di un altro studio incluso)
- Solo abstract di conferenza / nessun dato completo
Report esclusi: Ragione A (n = ?) Ragione B (n = ?) …
Fase 4 — Inclusi
Riquadro: Nuovi studi inclusi nella revisione
Studi che hanno superato la valutazione del testo completo e sono entrati nella revisione. Se si esegue una meta-analisi, questi sono gli studi che contribuiscono dati ad almeno un'analisi.
Studi inclusi nella revisione (n = ?)
Riquadro: Report dei nuovi studi inclusi
Un singolo «studio» può avere più report (un trial può avere un articolo principale, un articolo sugli esiti secondari e un articolo di protocollo). Tenere traccia sia del numero di studi unici sia del numero totale di report.
Report dei nuovi studi inclusi (n = ?)
Studi precedenti (se si aggiorna una revisione precedente)
Se la revisione sistematica aggiorna una versione precedente, PRISMA 2020 aggiunge riquadri per studi e report riportati dalla versione precedente. Questi vengono mostrati in un'area ombreggiata nella parte inferiore della fase Inclusi.
Tabella di riferimento completa dei riquadri e dei conteggi
| Etichetta del riquadro | Cosa rappresenta il numero | Verifica del calcolo |
|---|---|---|
| Record da banche dati e registri | Tutti i risultati delle banche dati prima della deduplicazione | Somma di tutti i risultati di ricerca nelle singole banche dati |
| Record da altri metodi | Tutti i record non provenienti da banche dati | Somma per tipo di metodo |
| Record rimossi prima della selezione | Duplicati + esclusioni automatiche + non recuperati | Sottratto dal totale di identificazione |
| Record selezionati | Record visti da un revisore umano | Totale di identificazione meno rimossi prima della selezione |
| Record esclusi (titolo/abstract) | Non superato la selezione per titolo/abstract | Selezionati meno quelli avanzati al testo completo |
| Report ricercati per il recupero | Testi completi che si è cercato di ottenere | = Record avanzati dalla selezione |
| Report non recuperati | Testi completi non accessibili | Ricercati meno quelli effettivamente recuperati |
| Report valutati per l'idoneità | Testi completi letti | = Report recuperati |
| Report esclusi (con le ragioni) | Non superato la valutazione del testo completo | Valutati meno inclusi; le ragioni devono sommarsi al totale |
| Studi inclusi | Studi unici nella sintesi | Campione analitico finale |
| Report degli studi inclusi | Totale delle pubblicazioni per gli studi inclusi | Maggiore o uguale al numero degli studi |
L'aritmetica deve tornare
Una richiesta di revisione sorprendentemente comune è un'incoerenza nei numeri. Usare questi controlli prima di sottomettere:
- Identificazione → Selezione: (Record dalle banche dati) + (Record da altri metodi) − (Rimossi prima della selezione) = Record selezionati
- Selezione → Idoneità: Record selezionati − Record esclusi (titolo/abstract) = Report ricercati per il recupero
- Idoneità → Inclusi: Report valutati − Report esclusi (con le ragioni) = Studi inclusi
- Report maggiore o uguale a studi: I report degli studi inclusi devono essere maggiori o uguali al numero degli studi inclusi
Eseguire questi quattro controlli ogni volta che si aggiorna un conteggio.
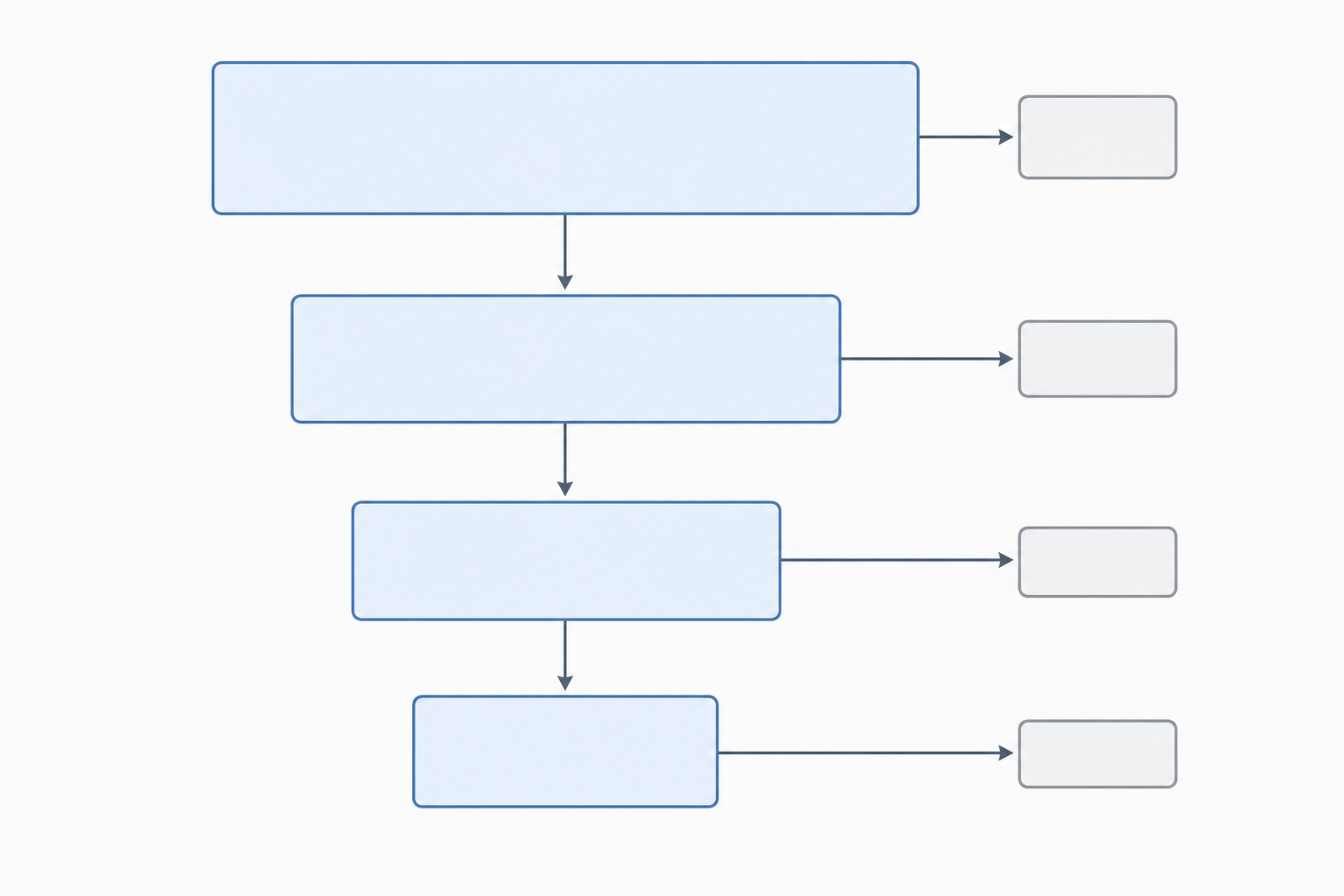 A ogni fase i conteggi devono tornare: record in entrata, meno quelli rimossi, uguale ai record che avanzano.
A ogni fase i conteggi devono tornare: record in entrata, meno quelli rimossi, uguale ai record che avanzano.
Errori comuni da evitare
Riportare il conteggio post-deduplicazione invece di quello pre-deduplicazione nel primo riquadro. Il primo riquadro di identificazione deve mostrare il totale grezzo da ciascuna fonte prima di rimuovere i duplicati. Il passaggio di deduplicazione è mostrato esplicitamente nel riquadro di rimozione.
Omettere le ragioni per l'esclusione del testo completo. Le ragioni di esclusione per titolo/abstract sono facoltative; quelle per il testo completo sono obbligatorie. Elencare ogni ragione e il suo conteggio.
Confondere studi e report. La fase Inclusi distingue tra studi unici e le pubblicazioni che li riportano. Mantenerli separati.
Non mostrare la colonna destra quando si sono fatte altre ricerche. Se si sono cercate manualmente riviste, esaminate liste di riferimenti o contattati esperti, quei record appartengono alla colonna destra — ometterli è un bias da segnalare.
Usare un template PRISMA 2009 per una sottomissione del 2020. Le due versioni si assomigliano ma differiscono nella terminologia e nella struttura. La maggior parte delle riviste richiede ora la versione 2020. Consultare la dichiarazione PRISMA 2020 (Page et al., 2021, BMJ) in caso di dubbi.
Formattazione del diagramma
PRISMA non prescrive font o colori, ma la convenzione e la leggibilità suggeriscono alcune buone pratiche:
| Elemento | Raccomandazione |
|---|---|
| Font | Sans-serif (Arial, Helvetica o Calibri); 8–10 pt per il testo dei riquadri |
| Stile dei riquadri | Rettangolo arrotondato per i riquadri di fase; rettangolo semplice per i riquadri di conteggio/rimozione |
| Frecce | Con una sola punta, piene; senza punte di freccia decorative |
| Colore | Il monocromo è sicuro per tutte le riviste; il riempimento grigio chiaro per i riquadri di rimozione migliora la leggibilità |
| Etichette di fase | Grassetto, tutto maiuscolo o in maiuscolo; posizionate all'esterno o sopra il primo riquadro in ogni fase |
| Formato file | Esportare come TIFF (300 DPI minimo) o PDF per la sottomissione alle riviste; PNG per i preprint |
Costruire il diagramma PRISMA con SciDraw AI
Disegnare il diagramma manualmente in PowerPoint, Word o Illustrator è noioso — ogni volta che un conteggio cambia è necessario rieditare i riquadri e reverificare l'allineamento. Un percorso più rapido è utilizzare uno strumento dedicato.
Il generatore di diagrammi di flusso PRISMA di SciDraw AI consente di inserire i conteggi direttamente in un modulo strutturato e genera automaticamente un diagramma correttamente formattato e pronto per la pubblicazione. Si possono regolare le etichette di fase, aggiungere o rimuovere la colonna «altri metodi», modificare le ragioni di esclusione ed esportare nel formato richiesto dalla rivista di destinazione.
Se il lavoro va oltre le revisioni sistematiche, il generatore di diagrammi di flusso di lavoro della stessa piattaforma gestisce i flussi di processo generali, le pipeline sperimentali e i diagrammi di metodologia a più fasi, utili anche per le sezioni dei metodi negli articoli di ricerca primaria.
Domande frequenti
È necessario utilizzare il template ufficiale PRISMA 2020? PRISMA fornisce un template Word compilabile sul sito PRISMA, ma le riviste non lo richiedono. Qualsiasi diagramma che contenga tutti gli elementi richiesti e conteggi accurati è accettabile. L'uso di uno strumento dedicato o il disegno della figura in software vettoriale va bene, purché il contenuto corrisponda alla checklist.
Cosa succede se un record appare in più banche dati? Va contato una volta nel risultato di ogni banca dati (contribuendo al totale pre-deduplicazione nel primo riquadro), poi tutte le copie tranne una vengono rimosse nel passaggio «Record duplicati rimossi». L'importante è che i numeri nel primo riquadro riflettano i risultati di ricerca grezzi in modo che i lettori possano valutare la sovrapposizione tra le banche dati.
Ho bisogno di diagrammi PRISMA separati per diversi esiti? In genere no — un diagramma copre l'intera revisione. Se si effettuano ricerche separate per domande di revisione distinte, diagrammi separati possono essere appropriati, ma questo è insolito. Discuterne con i coautori e verificare le istruzioni per gli autori della rivista.
Posso usare PRISMA per una revisione dell'ambito? Il PRISMA-ScR (estensione PRISMA per le revisioni dell'ambito) fornisce una checklist modificata. La struttura del diagramma di flusso è essenzialmente identica a quella di PRISMA 2020, quindi si applica la stessa logica dei riquadri.
Cosa sono gli «strumenti di automazione» nel passaggio di rimozione? Qualsiasi software che utilizzi l'apprendimento automatico o algoritmi basati su regole per contrassegnare i record come probabilmente irrilevanti prima della selezione umana. Esempi comuni sono la prioritizzazione AI di Rayyan, il motore di deduplicazione di Covidence e ASReview. Se non si sono utilizzati tali strumenti, omettere quella riga dal riquadro di rimozione.
La mia rivista chiede un «diagramma di flusso dello studio» — è la stessa cosa? Sì, nella maggior parte dei casi. «Diagramma di flusso dello studio», «diagramma di flusso PRISMA» e «diagramma di flusso della ricerca bibliografica» si riferiscono tutti alla stessa figura. Verificare se la rivista specifica esplicitamente la conformità a PRISMA 2020; in tal caso, seguire questa guida.


")
